
Amazon S3를 사용해 공유받은 데이터 다운로드
실습 데이터 소개
https://www.ncbi.nlm.nih.gov/sra/?term=SRR6327875
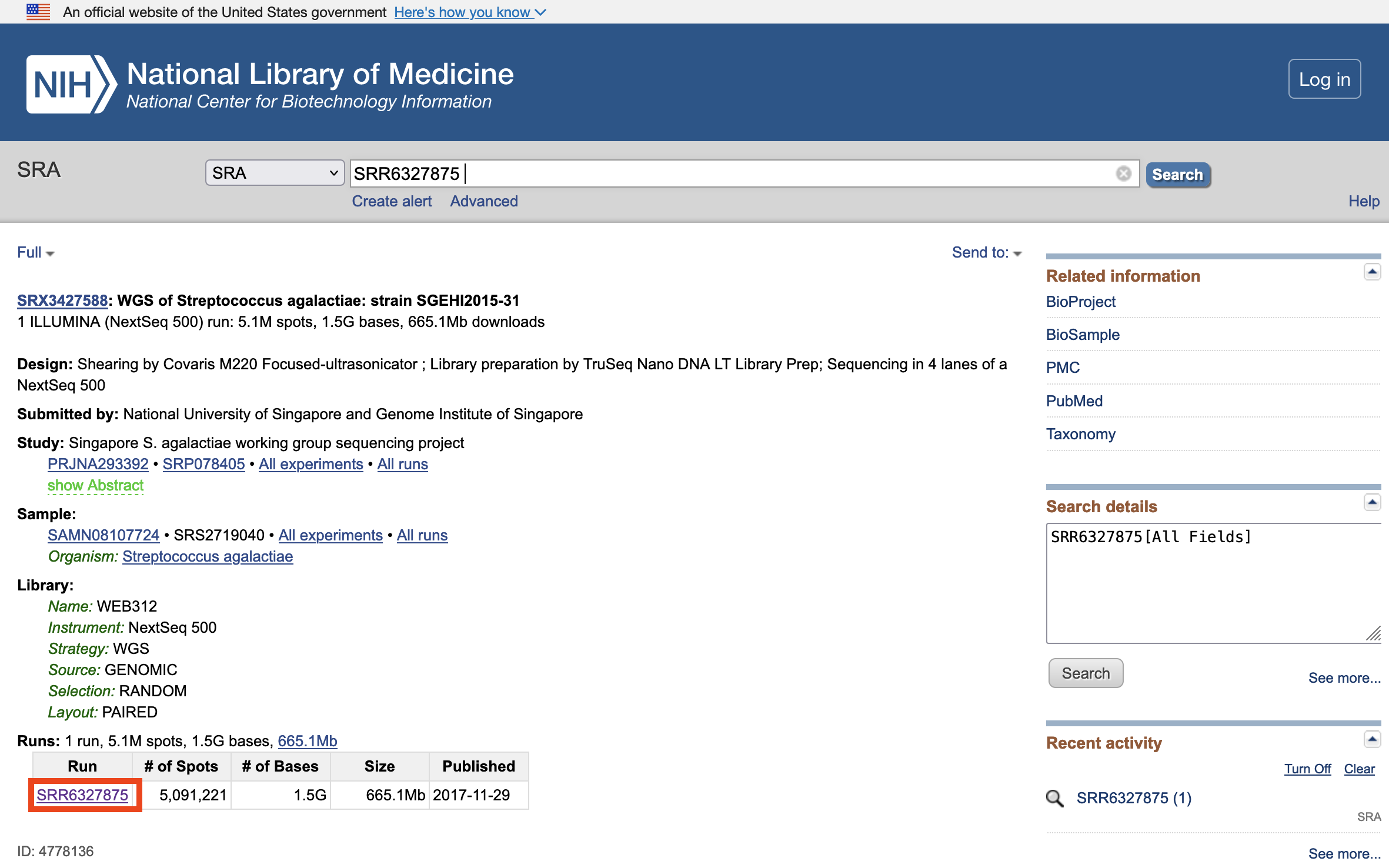
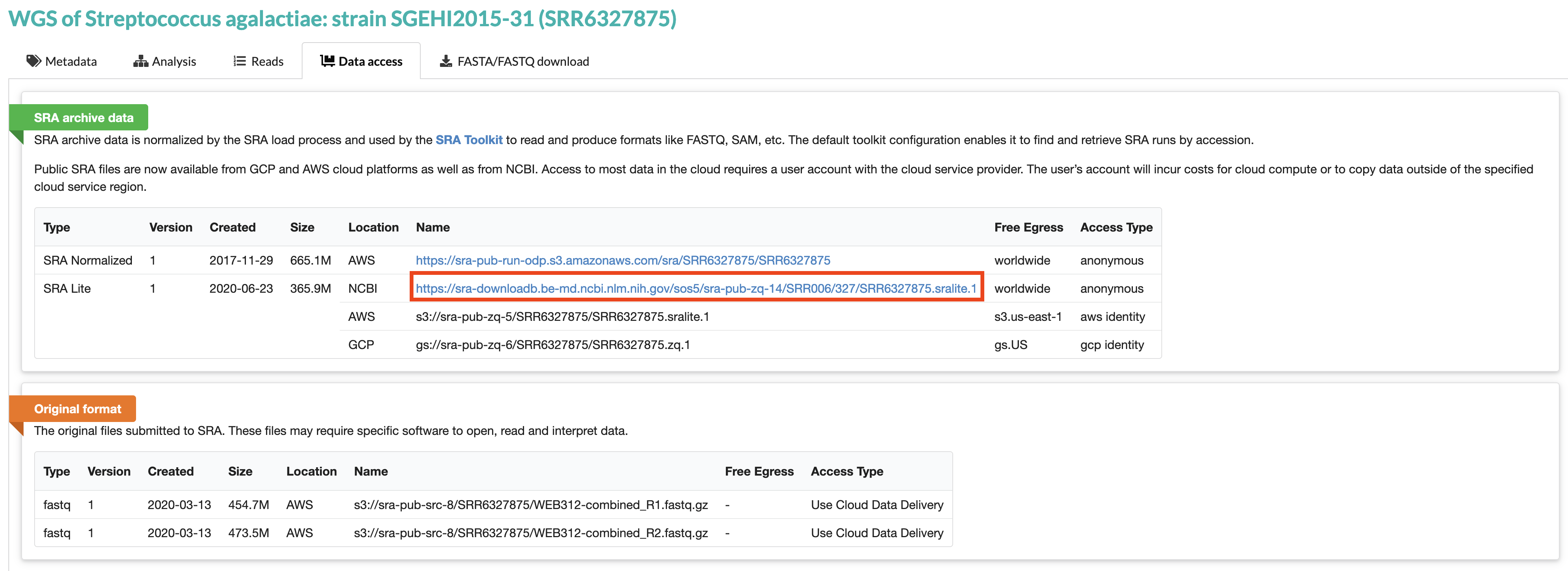
실습 데이터 준비
FOR KAIST SIIT Lab : 아래 다운로드만 수행합니다. R1, R2 파일 추출은 하지 않습니다.
다운로드
wget https://sra-downloadb.be-md.ncbi.nlm.nih.gov/sos5/sra-pub-zq-14/SRR006/327/SRR6327875.sralite.1R1, R2 파일로 추출
참고: c5.4xlarge 인스턴스에서 아래 명령어는 6분 30초 정도 소요되었습니다.
fastq-dump --split-files --gzip SRR6327875.sralite.1AWS CLI 사용을 위한 credential 적용
AWS에서 제공하는 워크샵 스튜디오를 통해 실습하는 경우 아래와 같이 Get AWS CLI credentials를 클릭하여 credential 정보를 얻을 수 있습니다.
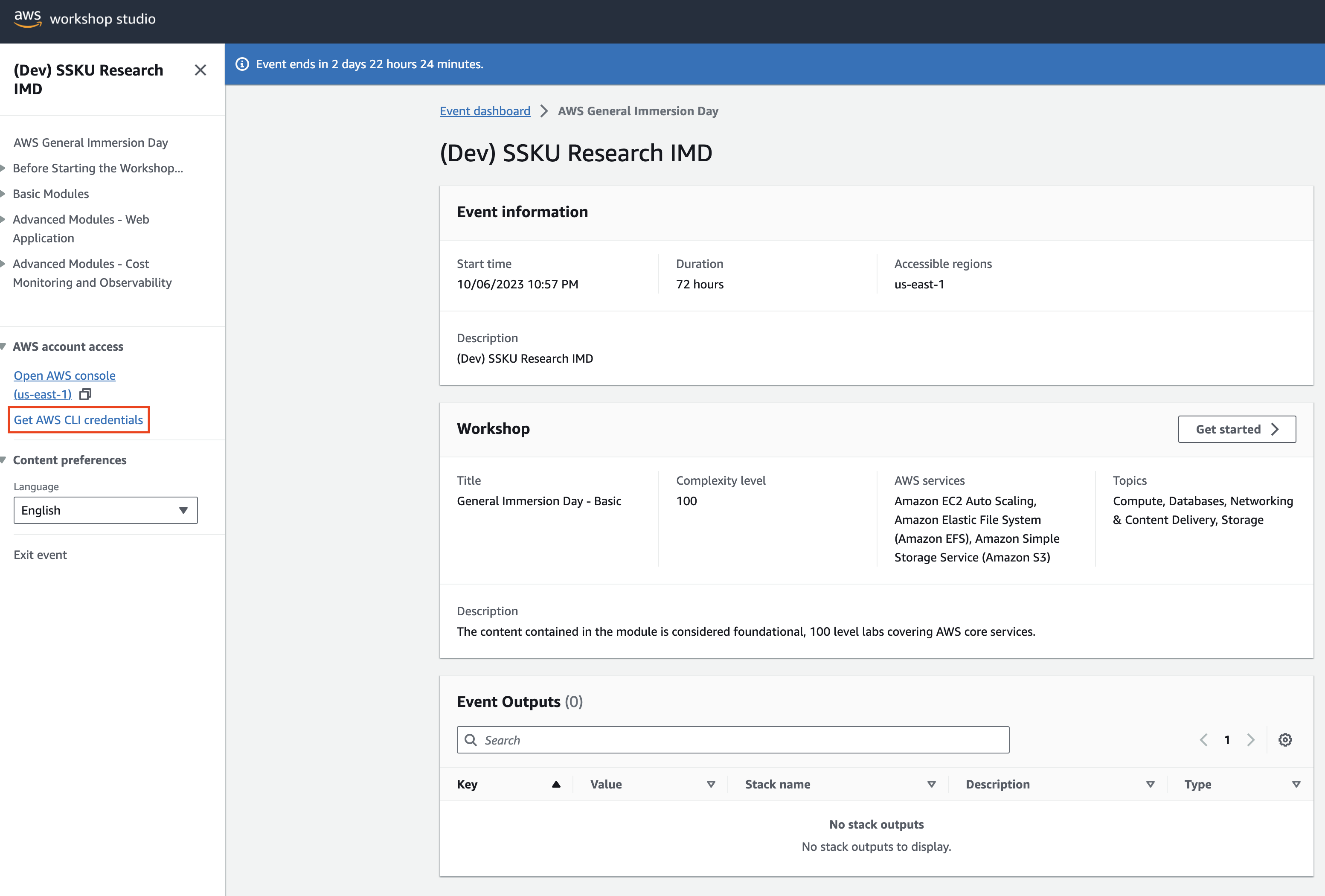
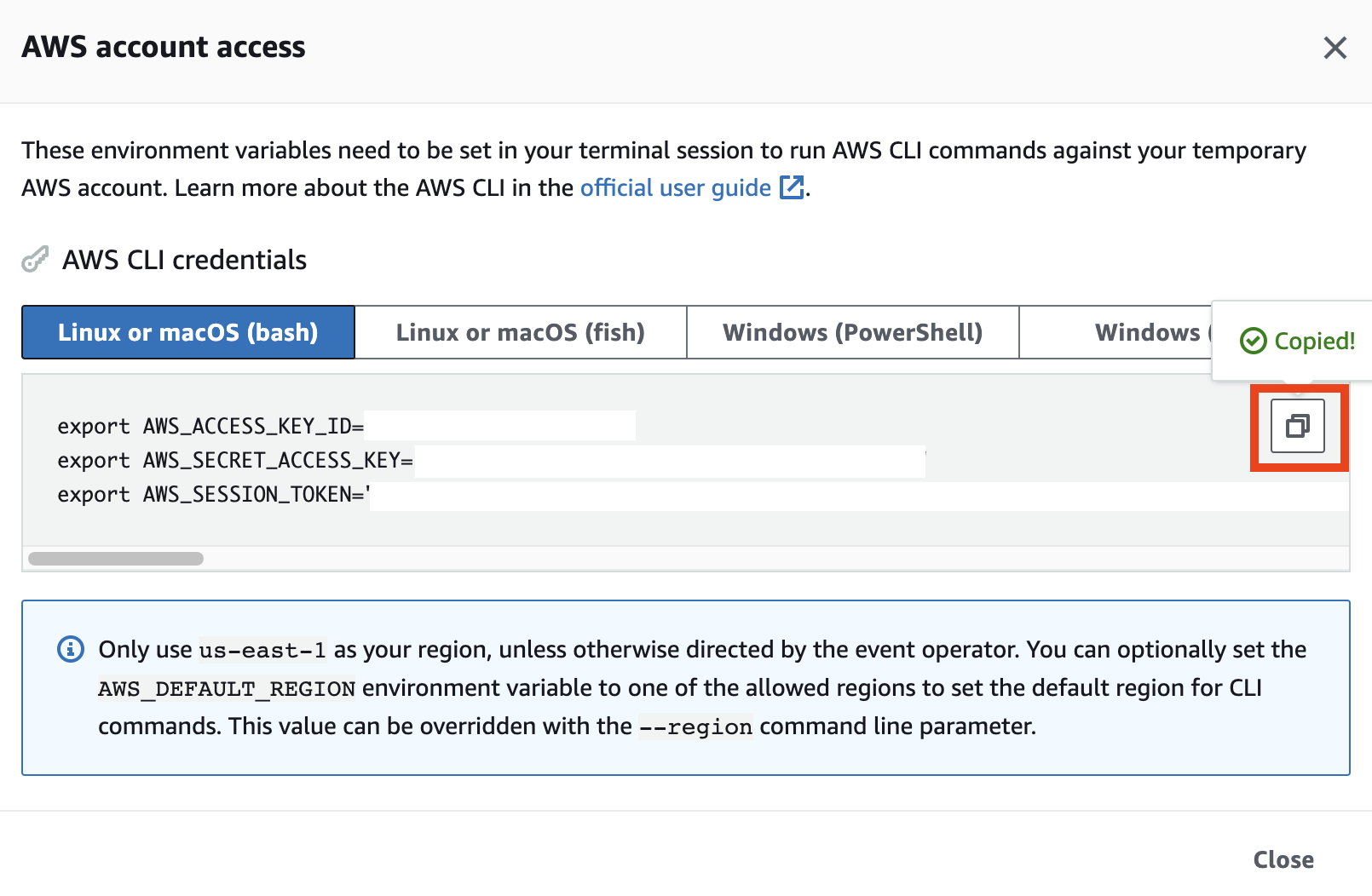
아래의 정보를 쉘에 복사하여 붙여넣습니다.
S3를 위한 AWS CLI 사용법
버킷 생성
이때 --bucket 의 값으로는 임의로 버킷을 생성하게 됩니다. 단, 전세계 S3 사용자 누군가가 이미 사용중인 버킷명은 사용할 수 없습니다.
여기서는 brandon-20230927 로 예를 들었습니다.
aws s3api create-bucket \
--bucket {본인의 버킷명} \
--region us-east-1
AWS 계정 내 생성된 버킷 확인
생성된 버킷은 S3 콘솔에서도 확인할 수 있습니다. (브라우저의 AWS 콘솔에서 S3 로 검색하고 선택)
S3로 데이터 복사 (FOR KAIST SIIT Lab : fastq.az 파일이 아닌 다운로드 받은 SRR6327875.sralite.1 파일을 복사합니다)
aws s3 cp SRR6327875.sralite.1_1.fastq.gz s3://{앞에서 만든 본인이 사용한 버킷명}/raw/SRR6327875_1.fastq.gz
aws s3 cp SRR6327875.sralite.1_2.fastq.gz s3://{앞에서 만든 본인이 사용한 버킷명}/raw/SRR6327875_2.fastq.gzFor KAIST SSIT Lab : 다음은 많이 사용되는 aws s3 명령어입니다. 자유롭게 s3 로 upload/download 테스트를 진행해보세요. 서브 폴더 생성과 테스트용 파일 업로드는 S3 콘솔에서 하셔도 됩니다.
자주 사용하는 AWS S3 CLI 명령어 :
1) S3의 폴더 내용 조회 (주의: recursive 앞에 마이너스 기호(-) 2개 사용)
; aws s3 ls
; aws s3 ls s3://aws-lab-james
; aws s3 ls --recursive s3://aws-lab-james
2) local 폴더를 서브폴더까지 s3로 upload
; aws s3 cp --recursive ./video/ s3://aws-lab-james/video/
3) s3 에서 local 폴더로 서브폴더까지 download
; aws s3 cp --recursive s3://aws-lab-james/video/ ./video/
4) local 폴더의 내용을 서브폴더까지 s3로 변경된 파일만 upload (cp 와 다르게 변경된 파일만 upload합니다. 삭제는 하지 않습니다)
; aws s3 sync ./video/ s3://aws-lab-james/video/
5) s3에서 local 폴더로 서브폴더까지 변경된 파일만 download (cp 와 다르게 변경된 파일만 download 합니다. 삭제는 하지 않습니다)
; aws s3 sync s3://aws-lab-james/video/ ./video/
FOR KAIST SSIT Lab : 아래 내용은 S3 에 업로드한 데이터를 기존 on-premise 나 노트북에서 다운로드 받아 사용하는 예제입니다. 이번 실습에서는 실행하지 않습니다.
S3 버킷에서 데이터 다운로드
이제 공유 S3 버킷에 액세스할 수 있으므로 S3 버킷에서 사용자 컴퓨터로 데이터를 다운로드합니다.
- 먼저 S3 버킷에 폴더를 나열합니다:
aws s3 ls s3://{앞에서 만든 본인이 사용한 버킷명}/raw/SRR6327875_1.fastq.gz --region us-east-1예) aws s3 ls s3://brandon-20230927/raw/SRR6327875_1.fastq.gz --region us-east-1
이제 이 폴더 내의 특정 위치에서 컴퓨터로 파일을 복사하겠습니다. 그 전에 이 데이터를 저장할 디렉터리를 컴퓨터에 만들어 보겠습니다.
- 다음 명령을 실행하여 데이터를 저장할 디렉터리를 만들고 해당 디렉터리로 복사합니다
mkdir -p /tmp/fastq/SRR6327875cd /tmp/fastq/SRR6327875- AWS CLI 명령어를 이용해 S3 bucket에서 새로운 디렉토리로 데이터를 다운로드합니다.
aws s3 cp s3://{앞에서 만든 본인이 사용한 버킷명}/raw/SRR6327875_1.fastq.gz .aws s3 cp s3://{앞에서 만든 본인이 사용한 버킷명}/raw/SRR6327875_2.fastq.gz . --region us-east-1- MD5 checksum을 통해 원본 파일과 S3에서 다운로드한 데이터를 비교해볼 수 있습니다.
md5sum *.fastq.gz
예)

5. S3의 NCBI SRA repository (Registry of Open Data on AWS)를 사용하여 다른 데이터 세트를 다운로드합니다:
mkdir -p /tmp/fastq/SRR6327950
cd /tmp/fastq/SRR6327950
# note here the --no-sign-request makes an anonymous request to this public S3 bucket
aws s3 sync --no-sign-request s3://sra-pub-run-odp/sra/SRR6327950/ /tmp/fastq/SRR6327950/
# convert the sra formatted file to fastq, then gzip them and clean up
fasterq-dump ./SRR6327950
gzip SRR6327950_1.fastq
gzip SRR6327950_2.fastq
rm -f SRR6327950이제 몇 가지 데이터 분석을 실행할 준비가 되었습니다.
---
(Optional) SRR6327875 데이터를 Registry of Open Data on AWS에서 마찬가지로 다운로드 받는 방법도 있습니다.
mkdir -p /tmp/fastq/SRR6327875
cd /tmp/fastq/SRR6327875
# note here the --no-sign-request makes an anonymous request to this public S3 bucket
aws s3 sync --no-sign-request s3://sra-pub-run-odp/sra/SRR6327875/ /tmp/fastq/SRR6327875/
# convert the sra formatted file to fastq, then gzip them and clean up
fasterq-dump ./SRR6327875
gzip SRR6327875_1.fastq
gzip SRR6327875_2.fastq
rm -f SRR6327875